引言
设计模式概念
设计模式(Design Pattern)的官方概念可以表述为:在软件设计中,设计模式是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。它是针对特定问题或特定场景的解决方案,是一种经过实践验证的最佳实践。设计模式主要用于解决软件设计中的各种问题,例如代码重复、性能问题、可维护性和可扩展性等。使用设计模式可以创建出可重用的解决方案,使代码更加清晰易懂、易维护和易扩展。设计模式不是语言特性或库,而是一种思想、一种方法论,它可以被应用于各种编程语言和框架中。学习设计模式可以提高设计能力和编程水平。
工厂模式概念:
工厂模式(Factory Pattern)是 最常用的设计模式之一,这种类型的设计模式属于创建型模式,它提供了一种创建对象的 最佳 方式。
工厂模式提供了一种创建对象的方式,而 无需指定要创建的具体类。
工厂模式属于创建型模式,它在创建对象时提供了一种封装机制,将实际创建对象的代码与使用代码分离。
特点:
创建对象时,- 不会对客户端暴露创建逻辑,并且是 通过 使用同一接口(API) 来指向新创建的对象
工厂模式的优势
工厂模式的优势主要体现在以下几个方面:
-
解耦:工厂模式将对象的创建与使用分离,使得代码结构更加清晰。当需要创建新的对象时,无需修改使用对象的代码,只需修改工厂类即可,这大大降低了代码的耦合度。
-
封装性:工厂模式隐藏了对象的创建细节,使用者只需知道所需对象的接口,而无需知道具体的创建过程。这增强了系统的封装性,使得代码更加易于理解和维护。
-
可扩展性:当需要添加新的产品时,只需在工厂类中增加一个新的产品创建方法,并修改返回类型或添加新的工厂子类,而无需修改使用对象的代码。这使得系统更加易于扩展。
-
灵活性:工厂模式可以根据不同的条件创建不同的对象实例。例如,可以通过配置文件或参数化工厂方法来创建不同的对象,这使得系统更加灵活。
-
符合开闭原则:工厂模式符合开闭原则,即对于扩展是开放的,对于修改是封闭的。当需要添加新的产品时,只需扩展工厂类而无需修改已有代码。
-
简化代码:通过工厂模式,可以将复杂的创建过程封装在工厂类中,从而简化使用对象的代码。同时,工厂模式还可以减少代码中的重复部分,提高代码的可重用性。
-
便于测试:工厂模式可以将创建对象的代码与使用对象的代码分离,这使得在测试过程中可以更容易地模拟或替换对象实例,从而便于进行单元测试或集成测试。
总之,工厂模式通过解耦、封装、可扩展性、灵活性、开闭原则、简化代码和便于测试等优势,使得系统更加易于理解、维护、扩展和测试。
工厂模式实现
(以下代码为例):
混乱的单文件代码
#include <stdio.h>
// 结构体实现类 -- 抽象
struct Animal
{
// 成员属性
char name[128];
int age;
int sex;
// 成员方法
// 注意这里是函数指针, if 不加上(), 就变成了返回值是 void*
void (*peat)();
void (*pbeat)();
};
void dogEat()
{
puts("狗吃屎");
}
void catEat()
{
puts("猫吃鱼");
}
void personEat()
{
puts("人吃米");
}
void dogBeat()
{
puts("d四你");
}
void catBeat()
{
puts("c四你");
}
void personBeat()
{
puts("p四你");
}
int main()
{
//简单的赋值方式
struct Animal dog = {
.peat = dogEat,
.pbeat = dogBeat
};
struct Animal cat = {
.peat = catEat,
.pbeat = catBeat
};
struct Animal person = {
.peat = personEat,
.pbeat = personBeat
};
dog.peat();
cat.peat();
person.peat();
dog.pbeat();
cat.pbeat();
person.pbeat();
return 0;
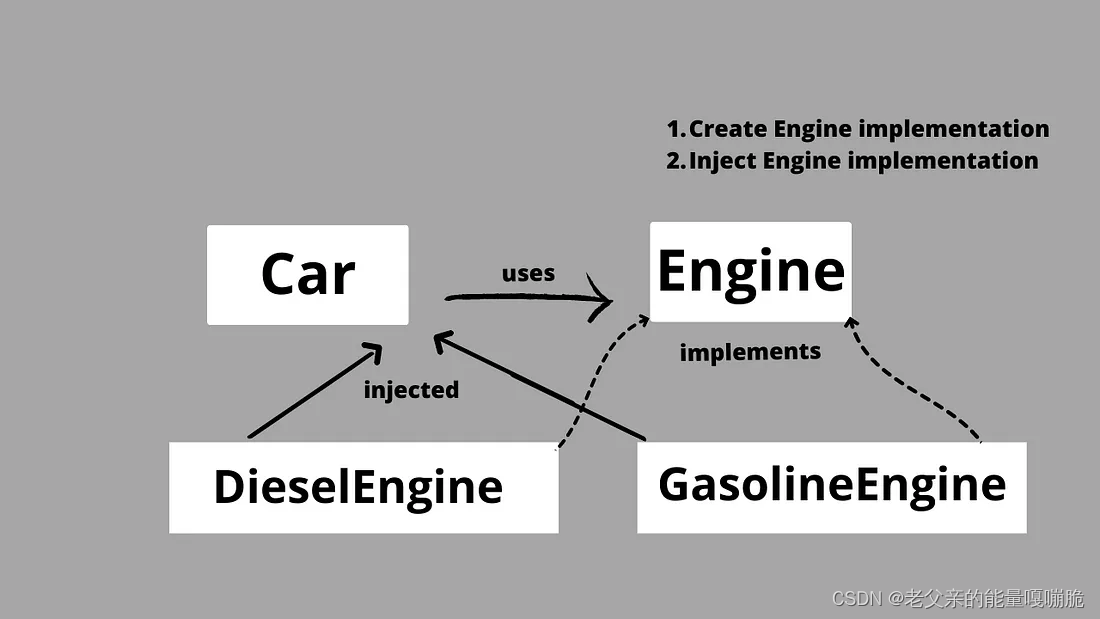
}工厂模式设计图:
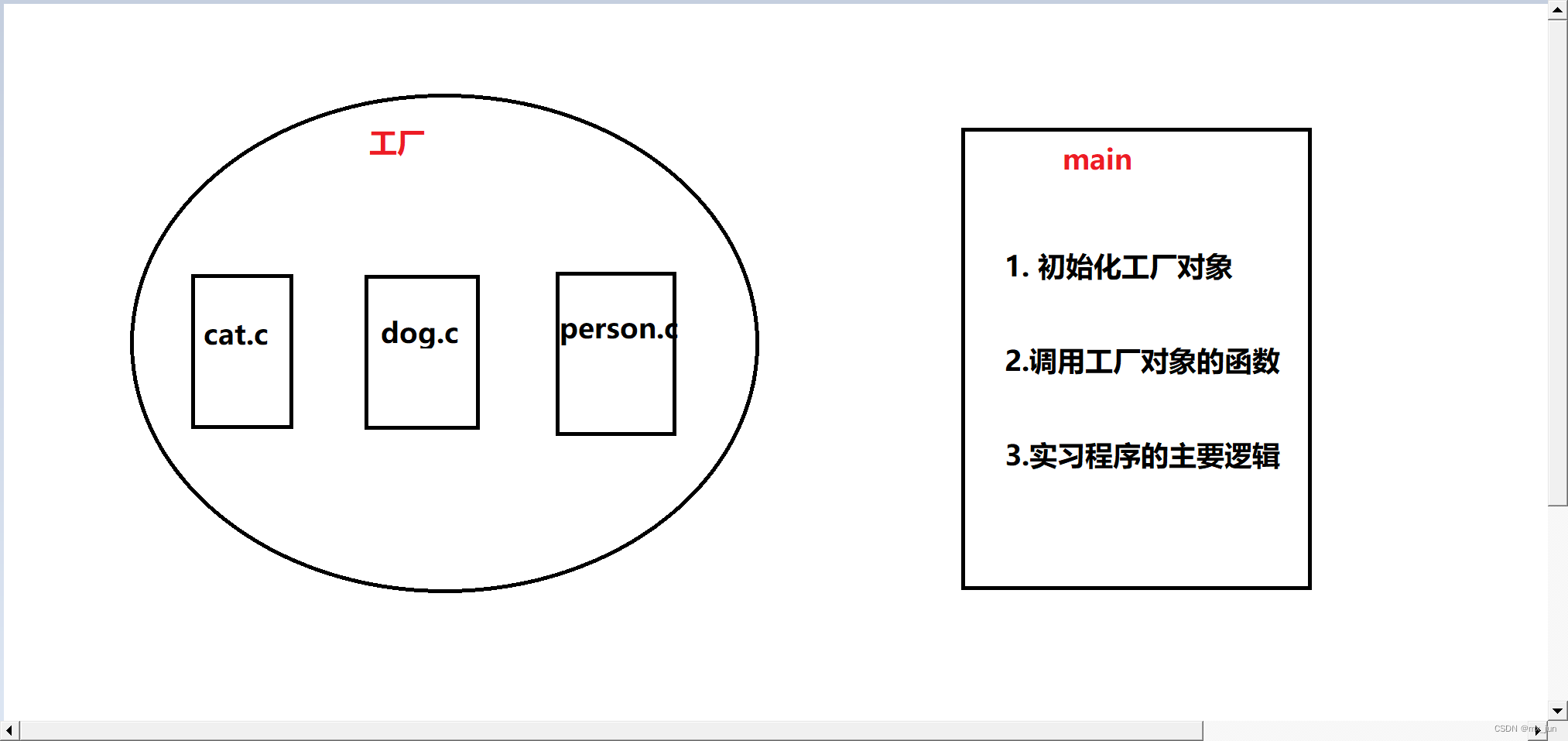
封装各个函数
记得把 main 函数需要 用到 .c(源文件)里面的函数,在需要包含的.h(头文件)中声明,不然 在main里面不能调用到
====================================
以下是全部文件
main.c
#include <string.h>
#include "animal.h"
// 链表的查找
struct Animal*findUtilByName(char *str,struct Animal*phead)
{
struct Animal* p = phead;
if(NULL == phead){
puts("空链表");
return NULL;
}
else{
while(NULL != p)
{
if(strcmp(p->name,str) == 0){
return p;
}
p = p->next;
}
}
return NULL;
}
int main()
{
char buf[128] ={'\0'};
struct Animal* phead = NULL;
struct Animal* ptmp;
//将我们需要的三种对象加入到链表中
phead = putCatToLink(phead);
phead = putdogToLink(phead);
phead = putpersonToLink(phead);
while (1) // 这就算我们需要实现的业务
{
puts("请选择你需要的对象,包括:Tom, huang, likui");
scanf("%s",buf);
ptmp = findUtilByName(buf,phead);
if(NULL != ptmp){
ptmp->peat();
ptmp->pbeat();
}
memset(buf,'\0',sizeof(buf));
}
return 0;
}==============================================
animal.h
#ifndef __ANIMAL_H_
#define __ANIMAL_H_
#include <stdio.h>
struct Animal
{
// 成员属性
char name[128];
int age;
int sex;
// 成员方法
// 注意这里是函数指针, if 不加上(), 就变成了返回值是 void*
void (*peat)();
void (*pbeat)();
struct Animal * next; //我们使用链表来遍历所有对象
};
struct Animal *putpersonToLink(struct Animal *phead);
struct Animal * putdogToLink(struct Animal *phead);
struct Animal * putCatToLink(struct Animal *phead);
#endif
==============================================
cat.c
#include "animal.h"
void catEat()
{
puts("猫吃鱼");
}
void catBeat()
{
puts("挠四你");
}
// 这里面的赋值 用到的函数 需要在前面先定义, 注意位置不能错
struct Animal cat = {
.name = "Tom",
.peat = catEat,
.pbeat = catBeat};
// 头插法 -- 向链表中添加猫对象
struct Animal * putCatToLink(struct Animal *phead)
{
// if(NULL == phead)
// {
// phead = &cat;
// }
// else
// {
// cat.next = phead;
// phead = &cat;
// }
if(NULL != phead) //if链表里面已经有数据的话
cat.next = phead; // 把cat插入头节点的后面
phead = &cat; //空链表 cat 就作为头 | 非空 cat 插入到头节点后面之后也会成为新的头
return phead;
}==============================
dog.c
#include "animal.h"
void dogEat()
{
puts("狗吃屎");
}
void dogBeat()
{
puts("咬四你");
}
struct Animal dog = {
.name = "huang",
.peat = dogEat,
.pbeat = dogBeat};
// 头插法 -- 向链表中添加猫对象
struct Animal * putdogToLink(struct Animal *phead)
{
if(NULL != phead) //if链表里面已经有数据的话
dog.next = phead; // 把dog插入头节点的后面
phead = &dog; //空链表 dog 就作为头 | 非空 dog 插入到头节点后面之后也会成为新的头
return phead;
}
person.c
#include "animal.h"
#include <stdio.h>
void personEat()
{
puts("人吃米");
}
void personBeat()
{
puts("骂四你");
}
struct Animal person = {
.name = "likui",
.peat = personEat,
.pbeat = personBeat};
// 头插法 -- 向链表中添加猫对象
struct Animal *putpersonToLink(struct Animal *phead)
{
if(NULL != phead) //if链表里面已经有数据的话
person.next = phead; // 把person插入头节点的后面
phead = &person; //空链表 person 就作为头 | 非空 person 插入到头节点后面之后也会成为新的头
return phead;
}// if 我们需要 扩展功能 --> 比如添加对象
这时候工厂 模式优势就体现出来了
常见问题:
fish.c:22:18: error: conflicting types for ‘putfishToLink’; have ‘struct Animal *(struct Animal *)’
22 | struct Animal * putfishToLink(struct Animal *phead) --> 这种报错通常是 源文件改了,但是头文件没有改
==========================
扩展
添加 fish.c
#include "animal.h"
void fishEat()
{
puts("大鱼小鱼");
}
void fishBeat()
{
puts("吐泡泡");
}
struct Animal fish = {
.name = "dayu",
.peat = fishEat,
.pbeat = fishBeat};
// 头插法 -- 向链表中添加猫对象
struct Animal * putfishToLink(struct Animal *phead)
{
if(NULL != phead) //if链表里面已经有数据的话
fish.next = phead; // 把fish插入头节点的后面
phead = &fish; //空链表 fish 就作为头 | 非空 fish 插入到头节点后面之后也会成为新的头
return phead;
}//然后我们只需要修改.h 头文件中包含的函数, 和main里面的逻辑
// 我们发现添加一次动物我们就需要去选项输出一次名字不太友好,那么我们可以优化遍历链表输出
新的main.c :
#include <string.h>
#include "animal.h"
// 链表的查找
struct Animal*findUtilByName(char *str,struct Animal*phead)
{
struct Animal* p = phead;
if(NULL == phead){
puts("空链表");
return NULL;
}
else{
while(NULL != p)
{
if(strcmp(p->name,str) == 0){
return p;
}
p = p->next;
}
}
return NULL;
}
void getAllName(struct Animal*phead)
{
struct Animal* p = phead;
if(NULL == phead){
puts("空链表");
}
else{
while(NULL != p)
{
printf("%s ",p->name);
p = p->next;
}
}
}
int main()
{
char buf[128] ={'\0'};
struct Animal* phead = NULL;
struct Animal* ptmp;
//将我们需要的三种对象加入到链表中
phead = putCatToLink(phead);
phead = putdogToLink(phead);
phead = putpersonToLink(phead);
phead = putfishToLink(phead);
while (1) // 这就算我们需要实现的业务
{
puts("请选择你需要的对象,包括:");
getAllName(phead);
scanf("%s",buf);
ptmp = findUtilByName(buf,phead);
if(NULL != ptmp){
ptmp->peat();
ptmp->pbeat();
}
memset(buf,'\0',sizeof(buf));
}
return 0;
}